Hugging Face is the definitive hub for individuals and organizations coalescing around the shared goal of “democratizing” AI. While open AI draws on the ideological values of open source software (OSS), the artifacts and modes of collaboration remain fundamentally different. Nascent research on the platform has shown that a fraction of repositories account for most interactions, ambiguous licensing and governance norms prevail, and corporate actors such as Meta, Qwen, and OpenAI dominate discussions. However, the nature of model-based communities, their collaborative capacities, and the effects of these conditions on governance remain underexplored. This work empirically investigates whether models—the primary artifact in open AI ecosystems—can serve as a viable foundation for building communities and enacting governance mechanisms within the ecosystem. First, we use interaction and participation data on Hugging Face to trace collaboration and discussions surrounding models. Second, we analyze governance variations across models with regular and growing community interactions over time.
We describe three phenomena: model obsolescence, nomadic communities, and persistent communities. Our findings demonstrate that the absence of robust communities hinder governance in artifact-driven ecosystems, ultimately questioning whether traditional principles of openness foundational to OS software can be effectively translated to open AI.
<ccs2012> <concept> <concept_id>10003120.10003130.10003233.10003597</concept_id> <concept_desc>Human-centered computing Open source software</concept_desc> <concept_significance>500</concept_significance> </concept> </ccs2012>
The 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT '25), June 23--26, 2025, Athens, Greece
DOI: 10.1145/3715275.3732206
The open source software (OSS) movement is deeply entwined with a philosophical and conceptual narrative of community, collaboration, and the production of a commons [8].
Core to the functioning of OSS are “communities of software developers [who are] sustained and reproduced over time through the progressive integration of new members” over the course of a project’s life-cycle [22].
This narrative has served as the ideological foundation for OSS projects, centering collaborative goals, shared ownership, and encouraging communal crisis-management [3, 13, 15, 40, 55].
Emerging work on governance and openness in AI evaluates the public availability and licensing of datasets, models, code, and documentation [44, 58].
This paper examines open AI through its relationship with the online communities developing and utilizing open AI models.
Unlike OSS communities which are built around repositories, code contributions, and licenses that facilitate iteration, co-creation, and disagreement, open AI communities engage with a broader set of artifacts including datasets, pipelines, and models. We argue that these artifacts of collaboration are fundamentally different. Open model artifacts do not naturally lend themselves to collaborative development or iteration. While software is continuously maintained and versioned to reflect changes over time [20], models are typically released as static outputs of a training process and rarely updated. Even models under the same branding may differ significantly in architecture, encoding, hardware, and training data [32, 61, 62]. In software, lines of code are attributable; up for debate and discussion in collaborative environments. By their very nature, however, machine learning models obfuscate the individual actions and choices that lead to their outputs. As a result, open AI ecosystems increasingly center on artifact consumption rather than collective creation.
Self-defined as a platform centralizing the “open-source AI community” Hugging Face is the definitive hub for individuals and organizations coalescing around the shared goal of “democratizing” AI. Yet, the nature of these communities, their governance structures, and their collaborative capacities remain under-explored. Hugging Face centralized infrastructure and tooling for pre-trained models, datasets, development and fine-tuning workflows [69]. Drawing on ideological narratives of OSS, for better or worse, the platform positions itself as a one-stop shop for open source applied machine learning and AI research. On Hugging Face, a small fraction of repositories accounts for most interactions, governance remains uneven (e.g. ambiguous licensing practices, incomplete model cards), and the platform is shaped by the influence of corporate actors such as Google, Microsoft, Meta, and OpenAI [9, 31, 48, 67]. These and other points of friction are indicative of the challenges of translating principles of openness and communal ties, foundational to OSS, into the open AI space. Motivated by these tensions, we ask:
RQ1: Do collaborative communities form around open models on Hugging Face?
RQ2: Do model communities grow and evolve over time?
RQ3: How do model communities govern themselves?
We apply a mixed-methods approach to these research questions. Building on Osborne et al. [48], we perform a quantitative analysis of data from the Hugging Face platform to reveal the patterns of community interaction around open models. We also perform a qualitative case-study analysis to illuminate governance themes within models with more persistent patterns of community interaction.
Our contributions are twofold. First, we empirically examine whether models, the central artifact in generative AI ecosystems, can serve as a viable foundation for building communities. We find that most models obsolesce quickly, some communities exhibit nomadic activity patterns, and a few groups maintain long term sustained communities. Second, we evaluate licensing and governance structures using the OSAID 1.0 as definitional guidance. Noting the inherent ambiguities in the OSAID, we propose an alternative Dual Openness Framework that distinguishes between process openness and use openness. This simple, inductively grounded taxonomy helps clarify governance challenges specific to open AI. Our findings demonstrate that the absence of robust, sustained communities hinder governance in artifact-driven ecosystems, ultimately questioning whether the principles of openness foundational to OSS can be effectively translated to open AI.
Two years after the public release of ChatGPT, the Open Source Initiative (OSI) introduced a draft definition to clarify what qualifies as “open” in AI systems [38]. The draft aimed to apply long-standing OSS norms of transparency and collaboration to AI and LLMs. Critics argued it failed to account for AI-specific complexities like datasets, architectures, and training pipelines, and warned it could enable “open-washing.” In October 2024, OSI released OSAID 1.0, requiring full transparency of models, weights, data, and processes. Despite this effort, the open AI ecosystem has largely advanced independent of formal standards with organizations and individuals referring to artifacts as open regardless of compliance with the OSAID.
OSS communities have long been heralded as exemplars of geographically disparate and decentralized collaboration [55]. These communities manage common pool resources [49] and become recursive publics [40]; technical communities motivated by a collective goal to sustain the infrastructure that enables their existence [13, 15, 16]. GitHub exemplifies how collaborative infrastructures have evolved to centralize and streamline OSS workflows [12, 23]. OSS communities on GitHub grow alongside their projects taking a variety of interaction topologies across repositories [23]. According to Yamashita et al. [71], these topologies can be characterized by “magnetism,” which refers to the ability to attract new contributors, and “stickiness,” which refers to the ability to retain them.
Onboarding new contributors and integrating them into a project only requires the ability to synchronize edits to source code. The affordances of textual code naturally support decentralization. Software engineering practices such as modular design [50], code testing [2], and clear separation of concerns [21] further strengthen the capacity for distributed collaboration. While the broader AI ecosystem shows some decentralization, especially across tasks like data collection and benchmarking, the core development of models remains highly centralized [12, 67]. Unlike source code, model training involves significant financial and computational costs, creating barriers to the kind of collaborative on-ramps that are common in OSS [23].
Collaboration in OSS ecosystems revolves around source code, which serves as a central, human-readable artifact that enables iteration, reuse, and collective problem-solving [4, 11]. Source code is accompanied by version controls, documentation, and licensing, which collectively sustain collaborative development [13, 19]. table A.1 in the Appendix compares the artifacts of collaboration in traditional OSS to analogous ones in ML ecosystems. While ML ecosystems allow for updates, such as training on new data to addressing model drift, the fixed nature of pre-trained models and the lack of incentives for ongoing modification or maintenance often discourage such efforts.
AI development pipelines, beyond training, are decentralized and multi-staged in nature. Unlike traditional OSS projects, where contributors often have direct oversight of the entire project, AI developers operate within a more fragmented ecosystem [68]. Data labelers might be party to an open source model that they are entirely disconnected from [43]. Datasets are produced and shared across many models. The lack of visibility into how models and datasets are reused, adapted,or remixed obscures accountability [18, 34, 46]. Even well-intentioned interventions, such as bias documentation or metadata tracking, often fail to endure as artifacts are modified and repurposed across projects [14, 19, 29].
Questions of ethics, risks, and responsibilities have been central to OSS, with communities redefining traditional notions of authority and ownership. Projects like Debian demonstrate how self-governance and decentralized participation allow communities to democratize access to technology [13, 15, 16]. Licensing innovations may expand the possibilities for collaboration but also raise difficult questions about fair use and intellectual property, creating persistent legal and ethical gray areas [33]. The inherently collaborative qualities of OSS development also involves contributions from many individuals, making it difficult to attribute responsibility for specific decisions and outcomes [46]. At the same time, the transparency inherent in OSS development models and distributed version control systems [57] can empower contributors to hold one another accountable, ensuring higher-quality outputs and more thoughtful design [34].
Open foundation models carry both benefits and risks [5]. They can be run locally, inspected, and fine-tuned for specific goals, including those that diverge from or challenge the interests of large technology companies. For example, researchers and developers can use these models to advance domain-specific applications, address underrepresented use cases, or contribute to scientific discovery in ways that proprietary models cannot easily accommodate. Advocates claim open foundation models are adaptable, accessible for educational purposes, and have the potential to “democratize” AI innovation [36]. Additionally, they also enable external audits, making it easier to identify biases, inefficiencies, or harmful features embedded in the model. However, open models may potentially introduce risks, particularly concerning misuse [5, 66] such as spear-phishing campaigns [36], generating disinformation at scale, and exacerbating societal inequalities. In specialized domains, open models may pose biosecurity risks by enabling the design of dangerous substances or malicious biological tools [30]. Other documented risks include generating child sexual abuse material (CSAM), hate speech, and automating surveillance, as outlined by Kapoor et al. [39] in a detailed analysis of open model use cases and risks.
Open AI systems face distinct governance challenges and invite greater regulatory scrutiny than closed ones. The EU AI Act, for example, imposes tiered compliance obligations on general-purpose AI providers. While openly licensed models benefit from reduced transparency requirements, this comes with risks, as the definition of “open” remains delegated to a yet-to-be-established EU AI Office [44]. This regulatory ambiguity makes clarity around the meaning of openness, as advocated by the OSI, more urgent. Open processes—especially access to training data—are central to enabling auditing for copyright violations, privacy violations, and potential biases. However, the release of open weights and datasets introduces a risk of misuse. Model producers are under pressure to demonstrate transparency while mitigating liability. In practice, licensing often imposes use restrictions, which, while well-intentioned, diverge from the OSI’s definition of openness [17]. These restrictions can act as “governance theater,” shielding publishers from liability without meaningfully addressing potential harms [24].
Quantitative analyses of Hugging Face demonstrate structural and operational patterns reminiscent of social networks [47]. For example, activity across repositories is highly imbalanced, with less than 1% of models accounting for the majority of downloads and likes [48]. This skewed distribution reflects both the dominance of a few widely adopted models and the marginal visibility of most projects. Further, the developer community exhibits a core-periphery structure, wherein a small group of prolific contributors drives collaboration, while the majority of users remain isolated. Among the most active contributors, collaboration is characterized by high reciprocity and low assortativity, where core developers interact across diverse subgroups. However, these patterns also underscore the influence of corporate actors like Meta, Google, and Stability AI, whose contributions dominate the platform.
Governance challenges within these spaces extend to transparency and licensing. Pepe et al. [51] identify significant gaps in model documentation: only 14% of models explicitly declare their training datasets, only 18% document potential biases, and merely 31% specify a license, highlighting pervasive ambiguity in licensing practices. This lack of clarity complicates collaboration, particularly when restrictive licenses or licensing incompatibilities arise. While governance mechanisms like model cards and ethical review processes have been proposed to address these gaps, they are often adopted in an ad hoc manner or not at all [65].
Dual-use risks further complicate governance, as AI models are general purpose technologies that can produce both productive and harmful outputs.
Platforms including Hugging Face, GitHub, and Civitai face the unique challenge of moderating generative tools, where potential harm is apparent only after deployment [31].
The GPT-4chan incidentGPT-4chan is a language model fine-tuned on a dataset from the /pol/ board of the 4chan website. The model replicated the hateful and harmful language of its training data and was subsequently deployed in an experimental setting where it participated in discussions on the original 4chan board, generating thousands of posts.
shows how challenging it is to anticipate misuse, yet interventions like stricter licensing, ethical review processes, and proactive transparency mechanisms are resource-intensive and hindered by the lack of regulatory clarity surrounding AI intermediaries.
Alternative frameworks, like the Model Openness Framework [64] stress similar dimensions such as source availability, open data, and open licensing. Organizing systems on a spectrum or gradient of openness highlights the temporal and partial nature of staged openness, which may align with corporate goals but falls short of creating truly open ecosystems [58].
Hugging Face has emerged as a valuable resource for researchers conducting empirical studies of model marketplaces [1, 31, 48]. While code for model development may be hosted on GitHub and developer discussions occur across Discord, Reddit and other specialized forums, Hugging Face stands as the primary site where community activity directly links to specific models. On Hugging Face, the model artifact, documentation, licenses, access controls, derivative works, usage metrics and community interactions all converge—creating a centralized hub for AI model ecosystems.
Similar to Osborne et al. [48] we use the Hugging Face Hub APIhttps://github.com/huggingface/huggingface_hub
to collect all models and their metadata (including model cards, tags, and downloads) between 2022-05-25 and 2024-12-10.
For each model we also collect a dataset of all threads, comments, and pull requests. We adhere to Hugging Face’s terms of service, and do not collect any private data.
The dataset collected encompasses 1,122,334 models from 247,838 authors; however, most models have no community interactions. Within our date range, only 94,997 models (8.5%) have discussion comments or pull requests, totaling 317,669 community interactions. The data and scripts used to collect and analyze the data are available for replication at https://github.com/imandel/Brief-and-Wondrous Sections and present our data analysis, while Section builds on these findings through case studies derived from the same dataset.
To trace governance norms and patterns within the smaller set of repos with sustained communities. We return to the definitional requirements of the OSAID 1.0https://opensource.org/ai/open-source-ai-definition
When we refer to a “system,” we are speaking broadly about a fully functional structure and its discrete structural elements. To be considered Open Source, the requirements are the same, whether applied to a system, a model, weights and parameters, or other structural elements. According to the OSAID definition, an Open Source AI is an AI system made available under terms and in a way that grants the freedoms to:
Use the system for any purpose and without having to ask for permission.
Study how the system works and inspect its components.
Modify the system for any purpose, including to change its output.
Share the system for others to use with or without modifications, for any purpose.
These freedoms apply both to a fully functional system and to discrete elements of a system. A precondition to exercising these freedoms is having access to the preferred form for making modifications to the system.
categorizes AI models included in the OSI’s sample list of open AI systems. We group these models based on whether they qualify as open per the OSI. We label: open, partially open, or closed. The OSI states, for example, that the BLOOM model [42] would likely comply if some legal terms were adjusted, but do not state what those terms are. Therefore, we take an additional step to qualitatively assess the licenses and restrictions of the examples cited in the OSAID. We highlight the recurring presence of the Apache 2.0 license across all three categories of openness. While Apache 2.0 governs open models like Pythia and OLMo, it also governs partially open models like StarCoder2 and Falcon, and even 2 closed systems: Grok and Mixtral. Practically, this means that the system’s license alone cannot fully dictate the degree of openness. Use restrictions on specific models are of equal significance to other governance mechanisms, including ‘gates’ requiring individual access requests, as well as controls on corresponding artifacts like model weights and training data.
Closed models (i.e., Llama3, Grok, and Phi-2) uniformly restrict access to training data, whereas partially open models (e.g., BLOOM and Falcon) introduce use restrictions via OpenRAIL that limit open access as defined by the OSI.
| Class | Model (Org.) | License | Restrictions |
|---|---|---|---|
| Closed | Grok (X) | Apache 2.0 | Training data |
| Phi-2 (Microsoft) | MIT | Training data | |
| Mixtral (Mistral) | Apache 2.0 | Gated access & Training data | |
| Llama3 (Meta) | Meta | Gated access & Training data | |
| Partially Open | BLOOM (BigScience) | RAIL-1.0 | Usage limits |
| StarCoder2 (BigCode) | Apache 2.0 | Usage limits | |
| Falcon (TII) | RAIL-M | Usage limits | |
| Open | Pythia (Eleuther) | Apache 2.0 | None |
| OLMo (AI2) | Apache 2.0 | None | |
| CrystalCoder (LLM360) | Apache 2.0 | None | |
| T5 (Google) | Apache 2.0 | None |
While the OSI provides these categorizations as definitional examples, they explicitly state that they do not “comprehensively assess AI systems beyond their licensing”Which AI Systems Comply with the OSAID 1.0? https://opensource.org/ai
[60].
This places the burden on model maintainers and end users to navigate both legal and artifact-level complexities, since the relationship between licenses and artifacts like model weights or datasets is less direct than in OSS.
Building on the OSI’s foundational definitions, we propose the Dual Openness Framework, to more transparently assess model governance across two key dimensions: (1) process openness and (2) use openness. In OSS, process and use openness are functionally collapsed. The language of OSI-approved licenses focuses on use openness. They are designed to create an unrestricted, fair playing field where individuals can collectively contribute to code with the assurance they aren’t competing with one another. Process openness is often implicit in open source software, though the quality of documentation, comments, and support varies considerably. Nevertheless, source code itself remains transparent, allowing processes to be approximately deduced through careful reading. In contrast, model weights are not clearly legible, requiring explicit calls for process openness.
Process openness refers to the availability of the technical tools and information required to replicate a model exactly bit-for-bit; including access to training data, model weights, random seeds, and detailed documentation of the training pipeline. This dimension captures the degree of lock-in and facilitates accountability. It also enables transparency for audits, such as verifying copyright compliance or ensuring the exclusion of personally identifiable information (PII).
Use openness pertains to the freedoms and limitations imposed on a model’s use upon release. This dimension includes restrictions that may prohibit harmful or irresponsible uses, such as generating child sexual abuse imagery, or creating biorisk threats. While such restrictions are often included to promote ethical use (e.g., through licenses like Open RAIL) [17], they can also raise concerns about compliance theater and the formation of counter-communities dedicated to jail-breaking models.
Through a four-category classification system, this framework accounts for variations in these dimensions:
Models that are process open but not use open
Models that are use open but not process open,
Models that satisfy both dimensions
Models that satisfy neither dimension.
A Dual Openness Framework also captures the two orthogonal normative concerns embedded in the OSAID 1.0. In the following section, we use this framework to assess governance objects for the top 10 models represented in figure A.1, and identify governance norms and patterns among models with consistent high-activity.
In the following section we present our findings on community activity patterns in open AI models. Models are the artifacts most commonly downloaded and used by Hugging Face Users. On Hugging Face, models are structured to resemble GitHub repositories, with Pull Requests, Issues, and Discussions grouped together under a “Community” tab which our analysis focuses on. We examine how contributor communities interact with models and how that relates to their governance structures. We consider the patterns of community activity aggregated at the model level. We also examine activity patterns at topic levels as users migrate from model to model.
With hosted version control tools like GitHub and GitLab, the repository is typically where most activity takes place. While activity may wax and wane with the popularity of a project, a regular user base of core developers will typically persist over time. We examine whether Hugging Face model communities exhibit a similar dynamic.
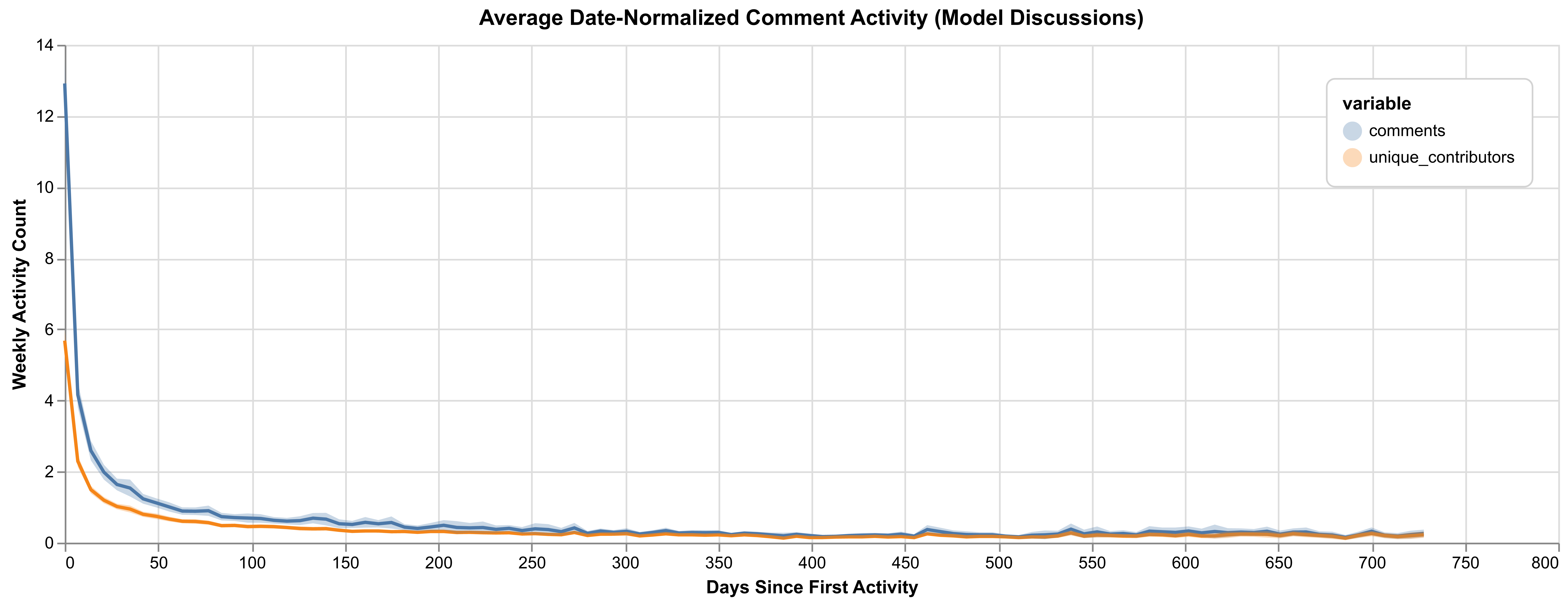
To ensure sufficient data for reliable evaluation, we filter for models with at least 100 days of total activity. The count of unique users and total activity are aggregated by week and aligned by the start date of the first activity in their community tab. This allows us to perform temporal comparisons over the life-cycle of a model. The visualization in figure 3.1 demonstrates how these aggregate values reveal an aggressive decline in model activity over time.
In general, models have an initial spike in both comments and unique contributors at the early stages of activity, with a sharp decline following the peak. Model discussions attract significant initial interest aligned with a new model or version release, but sustain only modest ongoing activity. On average, after approximately 50 days, the activity stabilizes at a consistently low level, demonstrating a “long tail” of engagement over time. Many models simply drop to zero engagement.
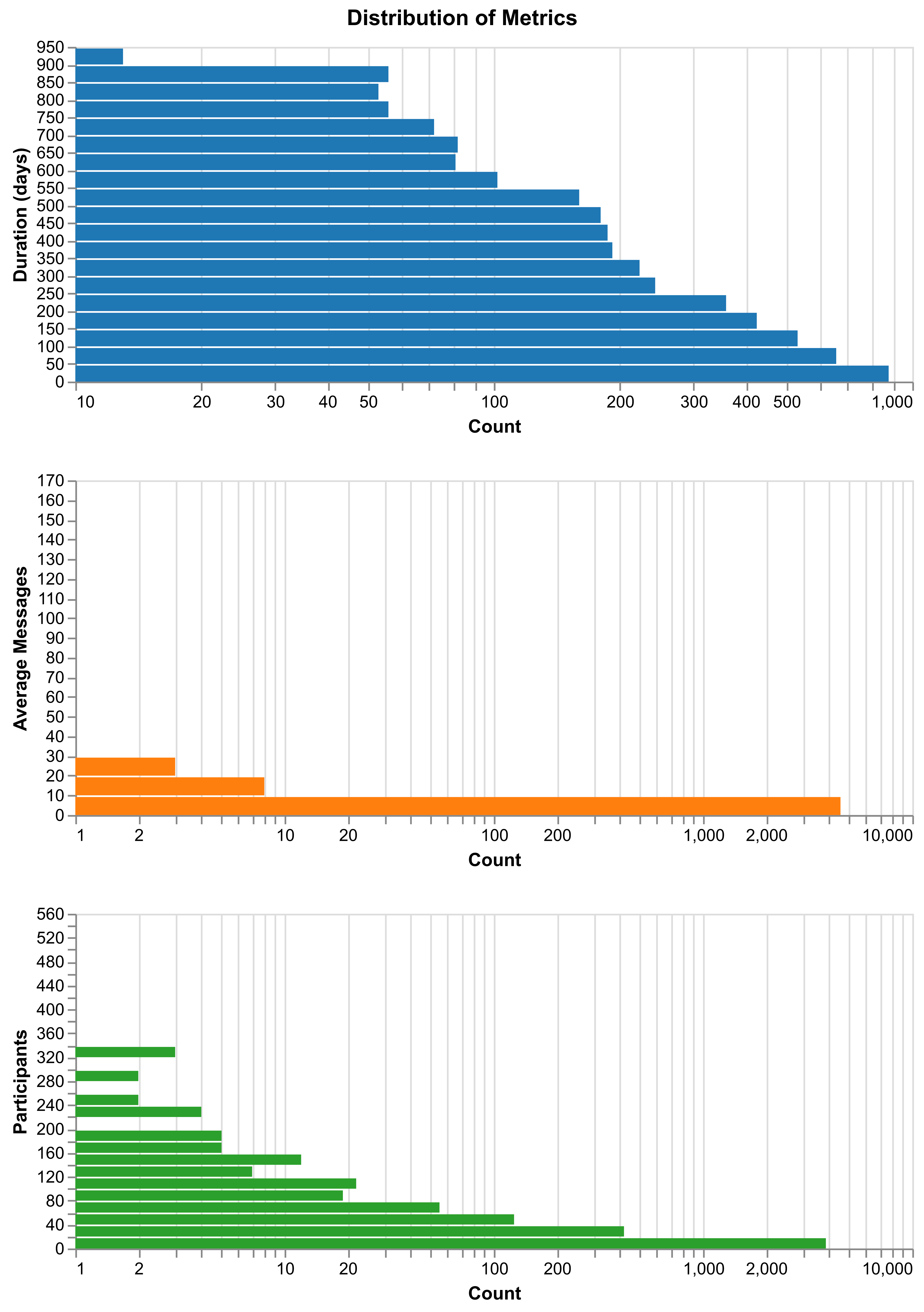
The top panel of figure 4.1 shows a skewed distribution for average activity duration, where the majority of models exhibit minimal activity duration. The mean duration of activity on a model is 43.49 days. This accounts for any and all activity, including a long tail of individual users and bots that extend the activity above zero without real community engagement. Most models have short-lived engagement, with only a few models maintaining activity over extended periods. The middle panel shows a steep skew in average actions or messages per model. Most models have low contribution activity, and only a small subset reaches higher levels of engagement. On average, participants contribute 1.58 comments or pull requests per model, with a variance of 25.69, reflective of highly divergent contribution levels among participants. The mean participant count over the life-cycle of a model is 1.96, suggesting that the majority of models receive comments from very few users. Most models attract very few participants, with only rare cases showing broader engagement. These metrics suggest that models on Hugging Face largely fail to serve as organizing artifacts for community formation, with interaction often limited to a handful of contributors.
Model-based communities on Hugging Face are short-lived and thus may lack the sustained engagement necessary for robust governance. The mean duration of activity for individual models is approximately 6 weeks, with very few models maintaining extended engagement beyond that. These findings suggest that individual models often fail to act as effective organizing artifacts for communities. We find similar patterns of interaction as Osborne et al. [48] and Casta\~{n}o et al. [9]— commits and pull requests from the community often focus on documentation rather than the core technical implementation of a model. This finding is consistent with models being treated as static artifacts once they have been trained and released. There is little incentive to continue updating existing model weights rather than allocating finite compute resources to develop a new and improved model.
We observe interaction patterns consistent with prior work [9, 48], where community contributions frequently center on documentation rather than modifications to a model’s core technical implementation. Beyond adding clarifying documentation, open source contributors operating outside a model’s development team have little opportunity to meaningfully contribute to what is effectively a static artifact.
.png)
Models exhibit ‘Burning Man’-style engagement patterns: intense but ephemeral collaboration that rapidly dissipates. Traditional OSS ecosystems often feature repositories that serve as infrastructural artifacts, fostering community cohesion throughout a project’s lifecycle. In contrast, models on Hugging Face are frequently superseded by newer improved models, resulting in a rapid decline in activity and eventual obsolescence.
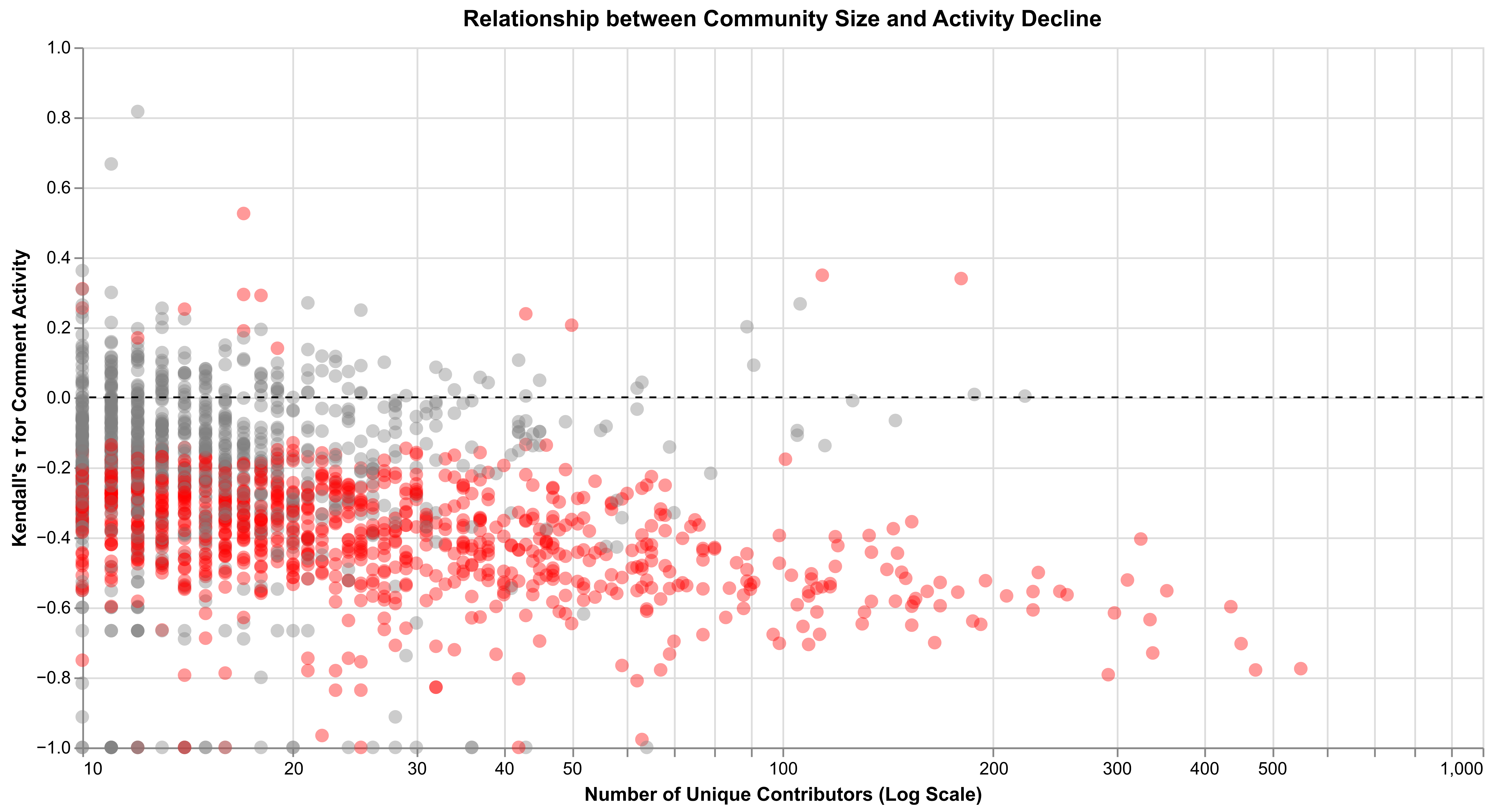
To examine the relationship between these trends and community size, we calculate Kendall’s τ rank correlation coefficient—as demonstrated by El-Shaarawi and Niculescu [25] and Chen et al. [10]—to measure the monotonicity of decline for individual models. As shown in figure 4.2, the overall trend falls below zero, indicating that model growth declines over time. Further, the larger the community, the stronger the downward trend. Larger communities ( > 100 contributors) consistently demonstrate moderate to strong declining trends (τ < −0.3). Red points indicate statistically significant trends (p < 0.05), revealing that larger communities are substantially more likely to experience significant declines in engagement over time. This pattern contradicts typical OSS dynamics, where greater popularity and activity generally correlate with enhanced longevity. In contrast, on Hugging Face, maintaining sustained engagement becomes increasingly challenging as communities grow, with nearly all large communities exhibiting drastic and systematic decreases in participation over time.
While individual model activity declines, the overall activity on Hugging Face over the study period increases dramatically throughout the study period. The last three months of the dataset show 769% more total comments and 1410% more model releases compared to the first three months, underscoring a substantial growth in platform-wide engagement despite the declines in per-model activity. The average comments per model stays relatively consistent in the time periods: 2.61 comments per model vs 2.75 comments in the last three months. The overall community grows even as individual models obsolesce with little to no persistent long term interaction. We examine how these trends occur across temporal patterns for specific topic focused communities.
In figure 4.3, we examine models tagged with MLX in their metadata. MLX is an array framework released by Apple Inc. optimized for machine learning on Apple silicon [35]. This reliance on a specific dependency and Apple hardware creates a centralizing effect, enabling us to more effectively isolate and observe this distinct community. Several other persistent communities exist but can be more difficult to detect solely using model tags. As described in , model activity peaks rapidly when a model is released and rarely, if ever reaches such heights again. Qualitatively, many of the comments represent discussions from users attempting to run the model locally and encountering technical issues. Most models have zero activity after the initial spike. However, we observe that these drop-offs are typically followed by successive activity spikes in other models as new releases emerge, indicating a nomadic pattern of community engagement. Even during periods of high comment activity, discussions are often dominated by a small subset of contributors. Importantly, there is a clear divergence between the two variables: intense but sporadic comment activity, and consistently low contributor diversity. These limits do not preclude alternative forms of community formation; rather, they point to the emergence of nomadic, cross-model communities operating fluidly across the ecosystem. MLX is not an outlier, we show similar examples in the Appendix for communities tagged with Text-to-Image (figure A.2), Art (figure A.3), Finance (figure A.4), Role-playing (Figures A.5 & A.6), and Not-For-All-Audiences (figure A.7).
These trends are a substantial deviation from temporal engagements with canonical OSS projects. There are certainly OSS communities known for churn; web development frameworks are one common example [26]. However, old projects are not abandoned wholesale. There are high switching costs that keep OSS projects “sticky,” keeping their communities active over time. For example, when switching to a new web framework “the time spent performing the migration is greater than or equal to the time spent using the old framework” [26]. A contrasting parallel case would be hostile forks such as the wholesale community shift from OpenOffice to LibreOffice [13, 28]. The OSS equivalent to the patterns observed on Hugging Face would be a hostile fork occurring every 50 days.
| Model | Organization | Description | License | Gate | Process* | Use** |
|---|---|---|---|---|---|---|
| BLOOM | BigScience | Multilingual LLM | RAIL-1.0 | No | Yes | No |
| Stable Diffusion v1-4 | CompVis | Text-to-image diffusion model | CreativeML | No | Yes | No |
| Whisper-large-v2 | OpenAI | Speech-to-text model | Apache 2.0 | No | No | Yes |
| OrangeMix | Individual | Anime image generation | CreativeML | No | Yes | No |
| Chatglm-6b | THUDM | English-Chinese chat model | Apache 2.0 | Yes | Yes | No |
| Geneformer | Individual | Transformer for single-cell transcriptomes | Apache 2.0 | No | Yes | Yes |
| Meta Llama 3 8B | Meta | Pretrained and instruction-tuned text model | Llama 3 | Yes | No | No |
| QR Code Monster | Monster Labs | Creative QR code generation | OpenRAIL++ | No | No | No |
| Mistral 7B0 v0.1 | Mistral AI | Pretrained generative text model | Apache 2.0 | Yes | No | No |
| XTTS-v2 | Coqui | Voice cloning | Coqui | No | No | No |
| Miqu 1 70b | Individual | Leaked Mistral model | None | No | No | No |
| Process Open: Whether the model’s training process is open. | ||||||
| *Use Open: Whether the model’s use is unrestricted. | ||||||
We rank repositories using the sum of weekly unique contributors, a metric that captures both the breadth and temporal persistence of community engagement. This approach prioritizes repositories with sustained participation over those with numerous one-time contributors or brief activity spikes. For instance, a repository with 10 consistent contributors engaged weekly for 10 weeks would rank higher than one with 50 contributors who participated only for a single week, despite having fewer total unique contributors overall. We exclude 3 outliers with large amounts of automated interaction or which do not actually host models. The top models can be seen in Figure A.1 in the Appendix. In table 4.1 we apply the Dual Openness Framework to the top ten models from that ranking. Using inductive thematic analysis [6, 7], we assess model descriptions, documentation, licenses, gates, and whether they are process and/or use open. We also examine all comments in all discussion threads for any community or governance themes [65].
Whereas the Model Openness Framework [64] focuses on the transparency of individual components (such as data, code, and weights), it does not offer a high-level lens for understanding how licensing shapes collaboration and governance. The Generative Gradient [58], on the other hand, frames openness along a spectrum with attention to safety and ethical concerns, but lacks structural clarity around the development and reuse of models. In contrast, the Dual Openness Framework distinguishes between use openness (the ability to access and apply a model) and process openness (the ability to reproduce, extend or contribute to it). This distinction provides a more pragmatic and governance-relevant typology that extends prior frameworks, helping both practitioners and researchers more precisely assess how licensing choices impact model stewardship and community participation.
Of the top ten models, five are process open and use restricted. Two models are closed, neither use nor process open (Llama3 and QR Code Monster). There is only one fully open model, Geneformer, released under Apache 2.0 without additional restrictions, Whisper-large-v2, is process closed, due to an absence of training data, but use open. Notably, Whisper-large-v2, despite being categorized as closed, uses the Apache 2.0 license, demonstrating, again, that a license alone cannot wholly dictate openness, as other governance mechanisms, such as access to training data and code—which OpenAI does not share—can override the permissive nature of the license.
We describe one model from each category in table 4.1 as case studies below:
Meta’s Llama 3 exemplifies a corporate governance model that imposes tight control through multiple access layers. Users must agree to the Terms of Use, Meta’s Privacy Policy, and the Meta Community License, while also providing personal and platform-specific information (such as their Hugging Face account credentials). The license includes several significant restrictions: it prohibits commercial use by companies with over 700 million monthly active users, it forbids using outputs to train other models, and it requires attribution on all deployments. Additionally, fine-tuned derivatives must incorporate ‘Llama 3’ in their name, further extending Meta’s branding control.
While both the organization and model cards are complete, the training data remains intentionally unavailable.
Community discussions frequently express dissatisfaction with access restrictions and the perceived lack of transparency in Meta’s decision-making processes.
One pinned discussion thread on Llama 3 “[READ IF YOU DO NOT HAVE ACCESS] Getting access to the model”, attempts to clearly state the steps required to access the model.Discussion #172: https://huggingface.co/meta-llama/Meta-Llama-3-8B/discussions/172
Among the 35 responses in the thread, several users report being unable to get past the license agreement gate. Others note that they declined to share their contact information with Meta and question whether that choice led to their access being denied.
Another discussion thread titled: “Your request to access this repo has been rejected by the repo’s authors” generated 53 responses, with many users voicing similar frustrations about access denials.Discussion #82: https://huggingface.co/meta-llama/Meta-Llama-3-8B/discussions/82
In several comments, users suggest workarounds by pointing to re-uploaded versions of the model weights shared by others.Discussion #87: https://huggingface.co/meta-llama/Meta-Llama-3-8B/discussions/87
The threads are highly participatory, with many members offering suggestions and commentary.
These specific use restrictions effectively reorient community interaction toward discussions about the existence and enforcement mechanisms of the restrictions themselves, rather than focusing on technical aspects of the model.
OrangeMix, a fine-tuned Stable Diffusion model, is created, hosted, and governed by an individual developer, WarriorMama777. The model card provides detailed technical specifications and describes the types of images it may generate, including NSFW content, though some sections are incomplete. It also includes a disclaimer placing responsibility for NSFW outputs on the user.
The disclaimer also states:
“I would also like to note that I am aware of the fact that many of the merged models use NAI, which is learned from Danbooru and other sites that could be interpreted as illegal, and whose model data itself is also a leak, and that this should be watched carefully.”OrangeMix Model Card: https://huggingface.co/WarriorMama777/OrangeMixs
Community discussions raise issues about commercial use and legal concerns: “Hello. While the description on this site can be translated as AOM3A1B being available for commercial use, other various sites indicate that commercial use is not allowed, and it’s unclear which is true. Is it actually possible to use it for commercial purposes?”Discussion #87: https://huggingface.co/WarriorMama777/OrangeMixs/discussions/87
Threads also cover model-specific prompting techniques,Discussion #78: https://huggingface.co/WarriorMama777/OrangeMixs/discussions/78
technical implementation,Discussion #66: https://huggingface.co/WarriorMama777/OrangeMixs/discussions/66
and creative suggestions, with active participation from a wide set of community members.
Whisper-large-v2 is a pre-trained model for speech recognition and translation, developed and governed by OpenAI. It is released under the permissive Apache 2.0 license and includes a complete model card, but OpenAI does not share its training data or training code.
Despite the permissiveness of the license, community discussions frequently raise questions about its commercial use and implementation.
In one thread, a user asked: “Can I use this openai/whisper-large-v2 model offline and for commercial purposes?”Discussion
#51: https://huggingface.co/openai/whisper-large-v2/discussions/51
Another responded by linking to the license file, confirming that commercial use is allowed.
We observe tensions between the openness of the model’s usage rights, and the closed nature of its development process, which leave users with limited agency to adapt or extend the model beyond the constraints defined by OpenAI.
A plurality of comments (29%) are made by one user employed by Hugging Face who answers a variety of technical support questions and guides users to resources.
Geneformer is a machine learning model that analyzes and predicts patterns in gene expression data.
This community is distinct in its focus on genomics and biological research. Geneformer is maintained by an individual representing a consortium of researchers, and has attracted a large contributor base. It is released under the Apache 2.0 license and includes a complete model card, which links to a Nature manuscript detailing the model and the group’s research goals.
While the majority of user comments are technical, a handful discuss governance topics include user confusion about accessing training data and issues replicating samples: “Hi, will you be including all of your code in order to replicate your analyses from your paper for validation purposes and to understand the technical work better? Also, I may be misunderstanding here but you do not include all of the code/data needed to replicate your examples...Any help on getting the model up and running would be appreciated thanks.”Discussion #48: https://huggingface.co/ctheodoris/Geneformer/discussions/48
Or, “I would like to raise an issue regarding the GeneCorpus-30M dataset. The dataset available is tokenized, and I am wondering if you could share the original data. We would like to experiment with different model architectures using the raw data. Thank you very much for your consideration?”Discussion #235: https://huggingface.co/ctheodoris/Geneformer/discussions/235
Each request received a response from the repository maintainer, and unlike many other models [9], the pull requests for Geneformer include substantive technical contributions rather than minor documentation edits.Pull Request #390: https://huggingface.co/ctheodoris/Geneformer/discussions/390
One comment raised a licensing issue, asking the maintainer to update the license file.Discussion #22: https://huggingface.co/ctheodoris/Geneformer/discussions/22
This comment appeared within the first month of Geneformer’s release on Hugging Face.
In this paper, we show how the rapid decline in model activity relates to the dual dimensions of openness, and how it differs structurally from OSS. In the following sections, we discuss the implications of our work.
Open AI communities are far more fragmented and diverse than traditional OSS ecosystems. While OSS projects, typically organize around a stable repository and develop long-term governance systems, open AI is marked by a wide variety of communities with distinct purposes. Some are strictly technical, focused on optimizing architectures or fine-tuning models (e.g., Mistral, BLOOM). Others form around domain-specific applications, such as Geneformer and OrangeMix. Open AI should not be viewed as a monolith, but as a constellation of both ephemeral and sustained communities. The nomadic behavior of many model communities further distinguishes open AI from OSS. Instead of forming persistent, model-centric collaboration hubs, users engage with one model intensely and then migrate to another as newer artifacts emerge. This form of fluidity, while unique to the open AI ecosystem, undermines sustainable governance structures, and community growth over time. Fleeting engagement with individual models also creates structural barriers to the development of communal norms, maintainer roles, sustainable collaboration, and accountability.
The OSAID framework requires that both process openness and use openness be satisfied for a system to qualify as truly open. Yet our analysis shows that many models fall short on one or both dimensions. In OSS, openness has a practical function: it creates a level playing field for building and sustaining a commons. Often, use openness alone is enough to support this. However, in open AI, the rapid obsolescence of models undermines that logic. If a model will soon be outdated, its immediate usability matters less than understanding how it was built. In these cases, process openness becomes much more valuable.
Similarly, we cannot wholesale replicate governance mechanisms from OSS with AI models. For example, forking in OSS provides dissenting contributors a governance mechanism to sustain project evolution. However, in open AI, such leverage is muted, as communities often abandon upstream models before forks can reconstitute meaningful governance structures. Within the context of open AI, forking will likely never provide similar leverage because the community will have already moved on.
The patterns of community activity seen in our case studies are closely shaped by both process and use openness. We do not make normative claims about which dimension is more desirable. Each has its own strengths and limitations. Rather, we argue that discussions of open AI should clearly specify what kind of openness is being referenced, in order to reduce ambiguity and mitigate potential downstream harms to users [9, 31, 48].
Contributors around open AI models do not iteratively improve a shared codebase. What emerges instead, in the open AI landscape are user communities, where individuals or groups engage with models primarily as tools for application rather than as artifacts to be collaboratively developed or extended. These user communities exhibit distinct patterns of interaction. Users, rather than having autonomy in the governance of open projects are more often grateful for the gifts given by model producers. Comments on repositories frequently take the form of requests for documentation, expanded access, or technical support rather than contributions. In some cases, when models are process open, communities engage in reproducing or fine-tuning the original model. The alignment between allowed uses and what a model is designed for shapes the productivity and enthusiasm of user communities. For example, OrangeMix, a model purpose-built for generating anime, is surrounded by a vibrant and productive user base because use openness aligns with its intended purpose: a low-stakes, creative image-generation model. General purpose models like Llama3, in contrast, demonstrate challenges that arise when allowed uses conflict with community needs or expectations. Restrictive use policies (e.g., gates), and prohibitions on commercial applications or fine-tuning can frustrate users, leading to a community focus on bypassing Hugging Face restrictions rather than constructive engagement.
There are many open AI communities whose participation is not captured on Hugging Face. It has been well documented that Eleuther has a strong, distributed contributor community [52]. However, most of that interaction takes place on Discord, only ever linking back to Hugging Face as a store of weights. These communities extend beyond individual models and the Hugging Face platform, forming networks of developers that we observe operating across multiple ecosystems. The lack of “stickiness” in individual models helps explain the rise of cross-model communities on platforms like Discord and Reddit (e.g., r/LocalLlama). Future work should investigate these nomadic formations across multiple platforms to more fully map the collaborative landscape of open source AI.
Open AI has uncritically ported the rhetoric, infrastructure, aesthetic and tools of Open Source Software. In doing so, it has created undue ambiguity in what “open” can and should mean, and what it is meant to accomplish. In this work we demonstrate that the technical and social affordances of open AI models are different from open source code in ways that fundamentally problematizes openness as it is practiced on Hugging Face.
As long-term participants in open source communities—serving as maintainers, contributors, and users—we acknowledge our positionality in relation to this study. This interdisciplinary collaboration draws on expertise in computer science, HCI, law, philosophy, and ethics. Motivated by the lack of empirical research on open model communities, our work spotlights the often-overlooked labor of individual maintainers and user communities who build and maintain social infrastructure within the open AI ecosystem. Our analysis focuses on the persistent legal challenges that these communities of non-legal experts encounter. We foreground the services these communities provide, illuminate their vital contributions to the open AI ecosystem, and advocate for greater recognition of their labor.
We are thankful to the Digital Life Initiative and The Cornell Tech Research Lab in Applied Law and Technology (CTRL-ALT) for providing space to workshop our ideas at various stages of this project. We are especially grateful to our brilliant colleagues and mentors: Solon Barocas, Severin Engelmann, Kat Geddes, James Grimmelmann, Brandon Liu, David Mimno, Eben Moglen, Helen Nissenbaum, and David Gray Widder.
| Artifacts and Attributes | OSS Ecosystem | ML Ecosystem |
|---|---|---|
| Documentation | README files, user guides, API documentation, developer resources [19, 54] | Model cards, architecture descriptions, and training logs |
| Source Code | Editable, versioned and reusable codebases for collaboration [27, 45, 56] | Model architectures (e.g., Transformers), code for training pipelines [41] |
| Forking Mechanism | The ability to fork repositories, allowing contributors to experiment, adapt, and propose divergent paths of development [28] | Forking models or datasets to fine-tune or quantize for new use cases[63] |
| Issue Tracking | Tools for bug tracking, feature requests, and project management (e.g., GitHub Issues) [37] | Reporting issues in pre-trained models or datasets [9] |
| Community Roles | Defined roles like maintainers, contributors, and reviewers [22] | Model creators, maintainers, and end-users |
| Licensing | Licenses for usage, modification, and redistribution (e.g., GPL, MIT, Apache) [13] | Licenses for models, datasets, and outputs (e.g., Apache 2.0, OpenRAIL) [53] |
| Discussion Forums | Mailing lists, IRC, Slack, or Discord for collaboration and support [59] | Discussion forums on model deployment, updates, and ethics [52] |
| Pretrained Models | N/A | Prebuilt models trained on large datasets for transfer learning (e.g., GPT, ResNet) |
| Model Weights | N/A | Learned parameters representing connections in trained models |
| Datasets | N/A | Curated data for training, validation, and testing (e.g., ImageNet, COCO) |
| Evaluation Metrics | N/A | Performance metrics (e.g., accuracy, F1-score, BLEU, ROUGE) |
| Energy and Resource Tracking | Rarely tracked explicitly | Logs on training costs for efficiency and sustainability [70] |
| Explainability Tools | N/A | Tools for interpreting model decisions (e.g., SHAP, LIME, attention maps) |